Model Architecture
All tasks share the same VAE encoder/decoder, MM-DiT backbone, and forward pass. Task identity is encoded solely by a channel-wise mask; source audio is concatenated as additional input channels in the latent space via VAE encoding. Text conditioning uses layer-wise deep LLM fusion: hidden states from uniformly sampled layers of the frozen Qwen2.5-Omni-7B backbone are injected into corresponding MM-DiT double-stream blocks via learned linear projections.
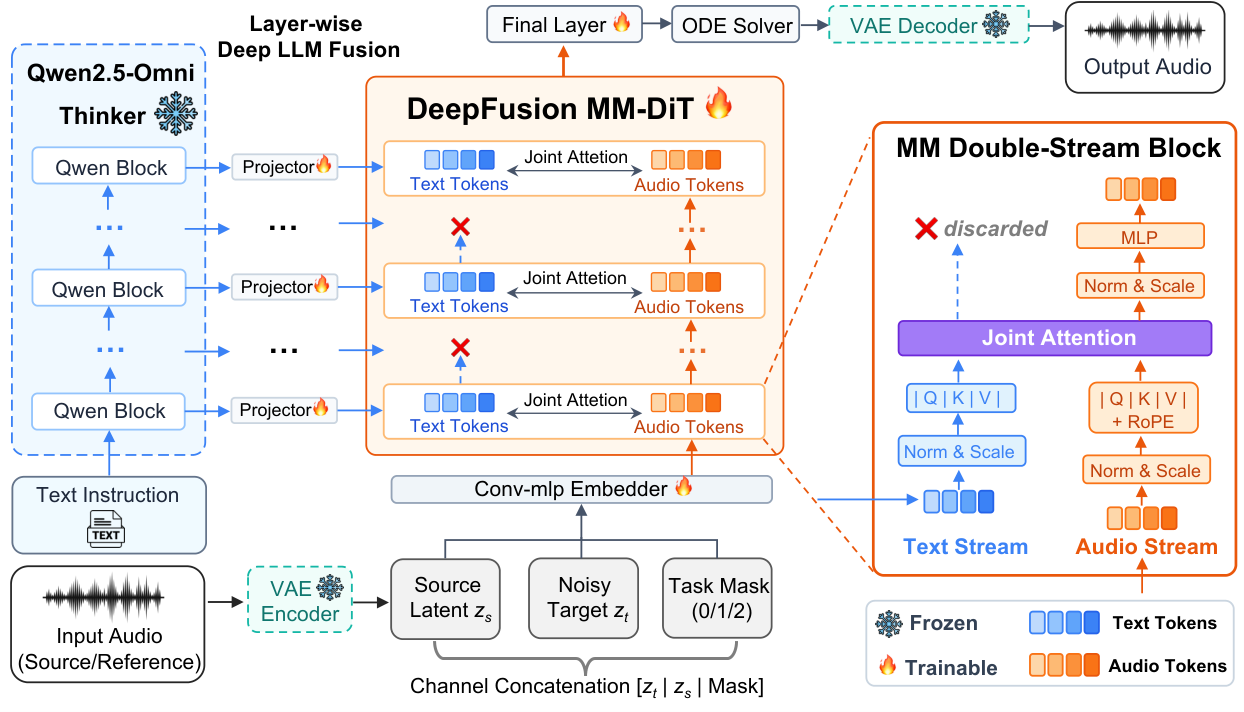
Figure 2. UNISON architecture. The frozen MLLM backbone (Qwen2.5-Omni-7B) provides layer-wise hidden states injected into the corresponding MM-DiT double-stream blocks via learned projections. Task identity is encoded by a channel-wise mask; source audio is provided via VAE-encoded channel concatenation.
Key Results (single checkpoint)
Text-to-Audio Generation
Input: a text caption of a sound scene.
Instruction format: [Audio] {caption}.
Source latent zs = zeros; task mask m = 0.
Output: 10-second audio clip.
Evaluated on the AudioCaps test set (881 clips).
| Prompt | Ground Truth | UNISON-16k (ours) | UNISON-44k (ours) | Audio-Omni | GenAU-L | Tango | MMAudio-L | Make-An-Audio 2 | AudioLDM2-Large | Stable Audio Open |
|---|---|---|---|---|---|---|---|---|---|---|
| Clip-clops gallop as the wind blows and thunder cracks | ||||||||||
| A train running on railroad tracks as a train horn blows and steam hisses | ||||||||||
| A very low-pitched hum occurs, followed by an explosion | ||||||||||
| Wind blowing followed by people speaking then a loud burst of thunder | ||||||||||
| A man speaking over an intercom as a helicopter engine runs followed by several gunshots firing | ||||||||||
| Footsteps shuffling on snow alongside a camera muffling while wind blows into a microphone | ||||||||||
| Tribal drums playing as footsteps shuffle on wet dirt as frogs and crickets chirp in the background |
Text-to-Speech (Instruction-based)
Input: a plain-text instruction specifying speaker gender and content.
Instruction format: [Speech] A {gender} voice saying “{text}”.
Source latent zs = zeros; task mask m = 0. No phoneme encoder or speaker embedding used.
Output: speech audio in the specified gender.
Evaluated on the Seed-TTS test set (EN & ZH).
Note: Audio-Omni does not support explicit gender control; its output defaults to a male voice and is shown in the male rows.
Audio-Omni also does not support Chinese TTS; those cells are left blank.
| Instruction | UNISON 16k (ours) | UNISON 44k (ours) | Audio-Omni |
|---|---|---|---|
|
EN · female
A female voice saying "It now has five chapters: Butterfield Trail, Magazine Mountain, Ozark, Razorback and Cornerstone."
|
— |
||
|
EN · male
A male voice saying "It now has five chapters: Butterfield Trail, Magazine Mountain, Ozark, Razorback and Cornerstone."
|
|||
|
EN · female
A female voice saying "Some large firms or specialized jobs require a master's degree."
|
— |
||
|
EN · male
A male voice saying "Some large firms or specialized jobs require a master's degree."
|
|||
|
EN · female
A female voice saying "He is a good player and deserves a chance at this level."
|
— |
||
|
EN · male
A male voice saying "He is a good player and deserves a chance at this level."
|
|||
|
ZH · female
A female voice saying “你是不是想死呀你,你问什么呀你。”
|
— |
||
|
ZH · male
A male voice saying “你是不是想死呀你,你问什么呀你。”
|
— |
||
|
ZH · female
A female voice saying “大大的眼睛望着镜头闪闪发亮,肉肉的小胳膊小腿也惹人怜爱。”
|
— |
||
|
ZH · male
A male voice saying “大大的眼睛望着镜头闪闪发亮,肉肉的小胳膊小腿也惹人怜爱。”
|
— |
||
|
ZH · female
A female voice saying “尾号四六七幺的乘客刚夸了你,你是电你是光,你是出行的神话。”
|
— |
||
|
ZH · male
A male voice saying “尾号四六七幺的乘客刚夸了你,你是电你是光,你是出行的神话。”
|
— |
Zero-shot Speaker Cloning
Input: a short reference audio clip (3–10 s) + target text.
Instruction format: [Speech with voice] {text}.
Source latent zs = VAE(reference clip + zero padding); task mask m = 2. No dedicated speaker encoder.
Output: full target utterance in the reference speaker's voice.
Evaluated on the Seed-TTS test set (EN & ZH).
| Target Text | Reference Speaker | Ground Truth | UNISON 16k (ours) | UNISON 44k (ours) | Audio-Omni |
|---|---|---|---|---|---|
|
EN · zero-shot
"The King of Portugal was being shaved by his barber."
|
reference |
||||
|
EN · zero-shot
"The bark of the pine tree was shiny and dark."
|
reference |
||||
|
ZH · zero-shot
"是对全球时装产业,与时装学院伟大成就的曼妙回眸。"
|
reference |
— |
|||
|
ZH · zero-shot
"顺风时提高警惕,逆风时笃定前行。"
|
reference |
— |
Mixed Speech-and-Audio Generation (T2AS)
Input: a joint instruction specifying both speech and background sound.
Instruction format: [Speech] … [Audio] …
(speech tokens describe what to say and gender; audio tokens describe the background soundscape).
Source latent zs = zeros; task mask m = 0.
Output: a unified audio clip containing intelligible speech mixed with the described background,
generated in a single forward pass.
| Instruction | UNISON 16k (ours) | UNISON 44k (ours) |
|---|---|---|
|
Speech (female) · EN
“She put on her slippers, scaled the stairs, and went to bed.”Background: A bird is cooing and flapping its wings |
||
|
Speech (female) · EN
“He chairs the executive committee of council and the community policing committee.”Background: Bee buzzes while man speaks |
||
|
Speech (male) · EN
“It then became involved with pharmaceuticals, food additives, and industrial and consumer chemicals.”Background: A man speaks with a high frequency hum and some banging and clanking |
||
|
Speech (male) · ZH
“目前,葛某及其朋友也被另案处理。”Background: Several very loud explosions occur |
||
|
Speech (female) · ZH
“二儿子同样是不会浪费时间的人。”Background: A piano playing as plastic bonks |
||
|
Speech (female) · ZH
“不光俺村群众不方便,谁从这过都不方便。”Background: Man speaks in a crowd, a distant horn blows, then a race car goes by |
Audio Scene Editing (Add / Remove / Replace)
Input: source audio clip + text edit instruction.
Instruction formats — Add: [Edit][Audio] Add {event}; Remove: [Edit][Audio] Remove {event}; Replace: [Edit][Audio] Remove {old} [Edit][Audio] Add {new}.
Source latent zs = VAE(source clip); task mask m = 1.
Output: edited audio clip.
Compared with MMEDIT, AudioEditCode (DDPM & SDEdit), and Audio-Omni.
| Edit Instruction | Source Audio | UNISON 16k (ours) | UNISON 44k (ours) | Audio-Omni | MMEdit | AudioEditCode (DDPM) | AudioEditCode (SDEdit) |
|---|---|---|---|---|---|---|---|
|
Add
Add Thunder to the background.
|
source |
||||||
|
Add
Add Bow-wow and Whimper (dog) to the background.
|
source |
||||||
|
Remove
Eliminate the sound of Gunshot, gunfire.
|
source |
||||||
|
Remove
Eliminate the sound of Bird and Domestic animals, pets.
|
source |
||||||
|
Replace
Remove the Duck. Add Sizzle.
|
source |
||||||
|
Replace
Remove the Burst, pop. Add Telephone dialing, DTMF.
|
source |
||||||
|
Replace
Remove the Bell. Add Truck and Skidding.
|
source |
Speech-in-Scene Editing (Insert / Delete / Rewrite)
Input: source audio clip (speech-in-scene) + text edit instruction.
Instruction formats — Insert: [Edit][Speech] Add a voice saying “{text}”; Delete: [Edit][Speech] Remove the speech; Rewrite: [Edit][Speech] Change speech to “{new}”.
Source latent zs = VAE(background) or VAE(background + old speech); task mask m = 1.
Output: edited audio with modified speech, background preserved.
| Edit Instruction | Source Audio | UNISON 16k (ours) | UNISON 44k (ours) |
|---|---|---|---|
|
Rewrite content
Alter the spoken content to “I will not be alarmed though your sister does play so well.”
|
source |
||
|
Insert speech
Add a voice saying “The facade is constructed from white Portland stone and red brick.”
|
source |
||
|
Delete speech
Remove the speech; keep the background sounds.
|
source |
Speech Denoising
Input: noisy speech recording.
Instruction format: [Edit][Speech] Denoise the record.
Source latent zs = VAE(noisy speech); task mask m = 1.
Output: clean speech waveform (background noise removed).
| Transcript | Noisy Input | Clean Reference | UNISON 16k (ours) | UNISON 44k (ours) |
|---|---|---|---|---|
|
EN · SNR 11.3 dB
“It does not comment on specific disputes.”
|
noisy |
clean |
||
|
EN · SNR 6.4 dB
“Man with guitar holding a microphone in one hand and extending his other arm.”
|
noisy |
clean |
||
|
ZH · SNR 9.4 dB
“乘车系好安全带,将你安全带向爱。”
|
noisy |
clean |
||
|
ZH · SNR 10.9 dB
“自动驾驶将为现有的司机运力提供补充。”
|
noisy |
clean |
Timed Temporal Composition
Input: a text instruction with explicit temporal anchors.
Instruction format: [Audio] From {t1}s to {t2}s, {event}. From {t3}s to {t4}s, {event}. …
Source latent zs = zeros; task mask m = 0. Timestamps parsed directly by the frozen LLM.
Output: 10-second audio where each sound event occurs at the specified time interval.
| Timed Instruction | UNISON 16k (ours) | UNISON 44k (ours) |
|---|---|---|
| From 0.0s to 3.1s, Ambulance (siren). From 3.6s to 6.1s, Chainsaw. From 6.6s to 10.0s, Subway, metro, underground. | ||
| From 0.0s to 4.1s, Thunder. From 4.6s to 10.0s, Stream. | ||
| From 0.0s to 4.2s, Rub. From 4.7s to 10.0s, Clip-clop. | ||
| [Overlapping] From 0.0s to 4.8s, Children playing. From 3.1s to 7.9s, Ambulance (siren). From 6.1s to 10.0s, Chainsaw. |